
Data Science is another buzz word today and every industry is looking forward to IT for solutions which can utilise Data Science research outcomes and brings the innovation it claims.
So that makes Data Science another job hiring hot skill like Cloud, DevOps, Blockchain etc. an ideal candidate for people looking for transition their roles in to one of the next gen digital skills or even fresh campus graduates who want to work on out of the box solutions on cutting edge digital skills.
Most of the people who want to learn one of these technologies whether they are college freshers out of the campus or experienced folks from different domains, have many common questions like what are the prerequisite? if it requires a programmer background ? how to start ? how to decide a track etc. And Data Science is no different in that aspect. People do have such questions and that is what I will try to discuss here from my perspective.

Specially people having significant experience in various IT domains which are becoming legacy have more specific questions regarding prerequisite and track which may compliment their previous experience so that they can smoothly transition their career on these new skills while leveraging their acquired skills over period of time in past roles. For freshers it is still a new skill they have to learn after formal education and they don’t have to face the similar challenges while opting a track as faced by experience people. We will briefly cover the freshers perspective but our focus of discussion will be more towards experienced IT professionals who are looking forward to learn Data Science related skills to target a role for their next move within same organization or outside organization.
Data Science adoption in industry creates mainly three tracks for people with different set of focused skills in each track. Data Scientist/Analyst is one of the mostly commonly heard term but that is not it, you have tracks like Data engineer and Data architect as well. To be fair anyone with no background in Data or coming from a different domain has to go through a common introductory training to understand the Tools, terms and ecosystem irrespective of any of the three roles they are targeting. We will talk about each role and respective track in a bit, before that lets talk about the common introductory knowledge required and some of the resources you may refer for the same.

The introductory course that you should choose to start with should be basic in nature and with no coding or in depth examples. The whole purpose of going through such course is to get familiar with terms and understand the ecosystem only.
Once you understand the terms and basics of ecosystem then comes the long term goal of picking a track and follow it. Here is some brief information about each track , I will try to explain track in way that should help you to relate your expectations in terms of prerequisite and can help you pick on of them.

Data Analyst – Some one who starts with this track will target Data scientist role in future. As a Data analyst you start with exploring data, cleaning it, analyzing it and making story out of it. You will write code in Python or R, you will know various data analytics platforms like tableau, PowerBI and Spotfire etc. You will learn to see pattern in data in this role, which is the first step towards Data Scientist. This is something a go to track for campus graduates and also someone having background of roles like data analytics or business intelligence. Being said that people from other background too can pick this track, its all about how you relate it with your passion and existing skills.
Data Scientist – This is the most famous word you hear when people talk about ML/Data Science/AI. In my opinion if you have experience in coding/scripting or inclination towards coding and statistics has been your thing then this might be something you can explore irrespective of your background. You will be expected to explore Algorithms, Statistics, recent research papers around ML/AI/Deep learning etc. You will write code and do a lot of analysis using various APIs like numpy, matplotlib, scikit-learn, tensorflow, fastai, etc. Apart from doing all cool coding stuff, analyzing data, building ML models, a good data scientist will have to understand the domain also (most important aspect if you see from industry adoption perspective). You supposed to explain those statistics results in terms what business understand i.e. how to use it to gain benefits in real business. You start like a Data analyst and with time and your understanding of various things you progress toward a Data Scientist. Someone either in Data analyst role or having inclination towards these expected tasks and skills can go for it. You have to plan this track with a long term goal in mind, as you will be expected to learn so many things to reach to a level to be called a Data Scientist. Plan it section wise, pick data analyst role may be and grow from there. Being said that you can directly transition to Data Scientist as well but keep in mind, its a long term commitment and will require a good planning.
Data Engineer – This is another role which is in demand now as more and more industries are trying to adopt various data science research results in to business. This is a role where you help the Data Scientist to build a enterprise ready platform to host their ML models, use it in LOB apps and get what business wants from Data Science. Data engineer should know the real tools, their configuration options, security aspects and all other IT infrastructure components to give Data Scientist a platform which works in enterprise environment. You will know various Big Data platforms like Hadoop or HDInsight, cloud offerings like Azure ML or Google AutoML, Container orchestration tools like kubernetes, and many other things in terms of IT infrastructure needed for a ML/AI application pipeline. You supposed to know the development environments used by Data Scientists and propose the relevant configurations in organization’s enterprise environment. Talking about scripting requirement, now as day by day Infrastructure as Code and programmable infrastructure are becoming norms you will be required to have or learn scripting in this role as well. This role is relevant for people coming from IT infrastructure background and want to transition their skills towards Data Science/ML domain.
A Data Engineer supposed to help with the flow below.
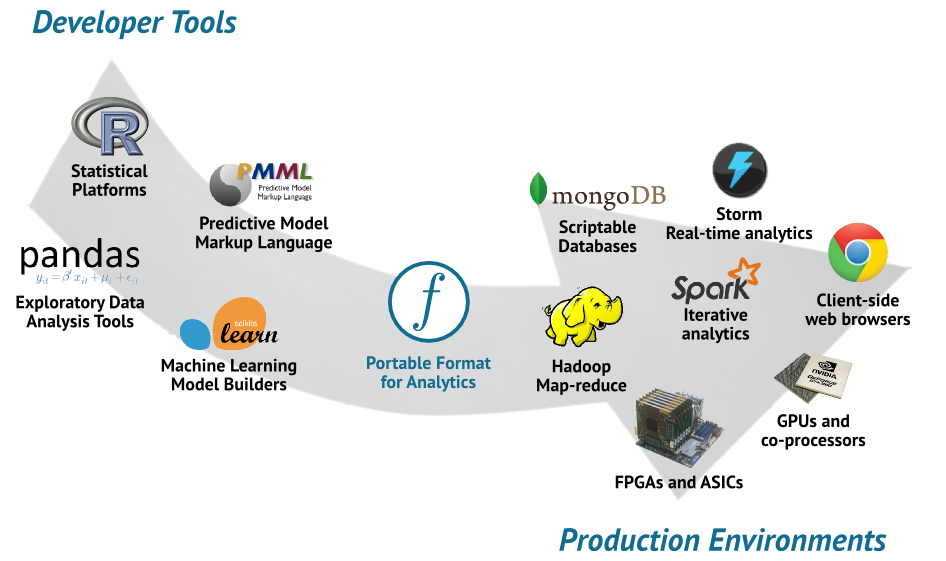
The flow is not limited to Tools being shown in above image , it only try to depicts a life cycle of a ML model adoption in production. Everyday new tools are coming to ease the development, transition and maintenance of ML model in production.
Please post your comments and resources you are using for respective track training.


Great Post and Great sharing, Looking forward to see more post from you .
Thanks for your comments Rahul!